How to Install and Use Docling for Document Processing 🚀
Saturday, Dec 14, 2024 | 7 minute read
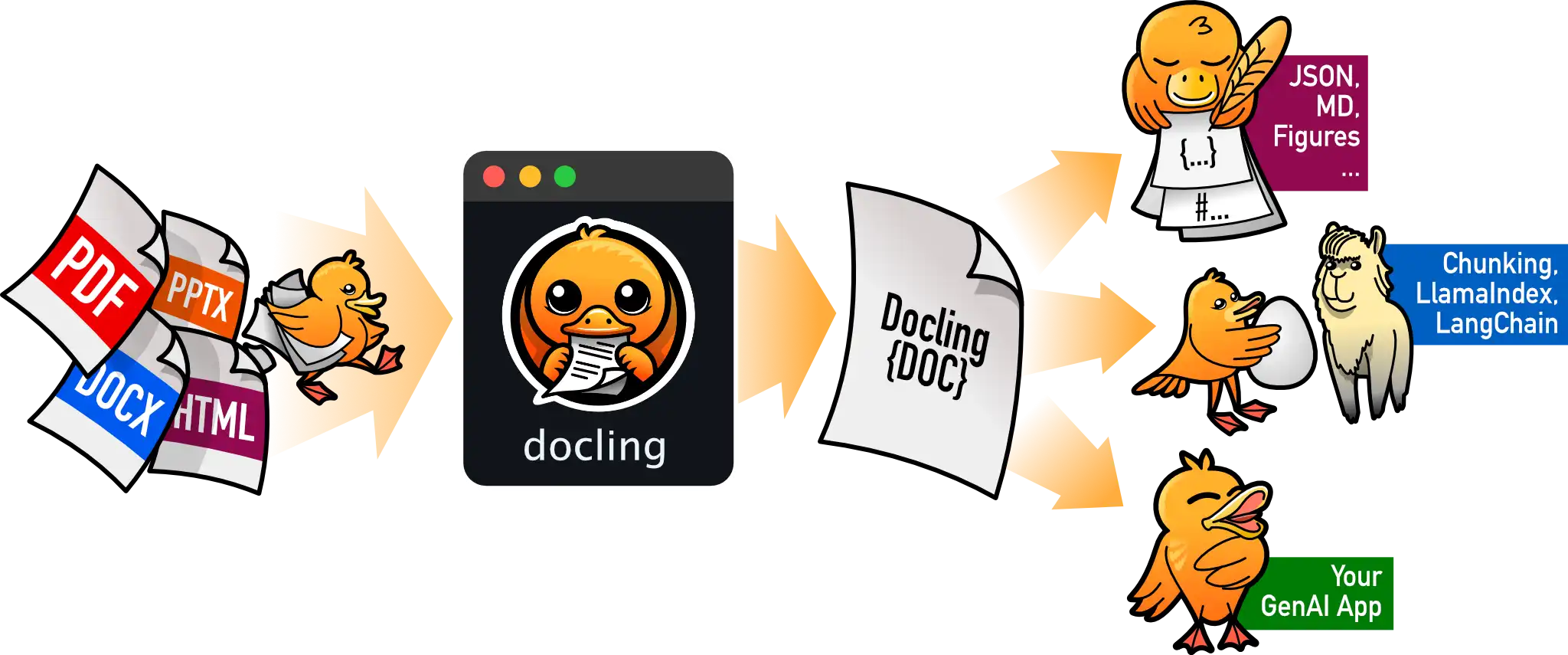
Unleash the power of seamless document processing! 🚀 This open-source tool offers hassle-free support for multiple formats, intuitive command-line interface, and robust integration capabilities, empowering users to boost productivity and tackle complex tasks effortlessly! 🌟💪
In this fast-paced era of information technology, document processing has long been an essential skill in modern work, while efficient document parsing tools serve as the key to enhancing productivity! 🔑
In this ever-evolving digital age, we face a myriad of documents daily, from work reports 📊 to contracts 📜. The diversity of document formats can often be overwhelming! 😩 Effective tools help us streamline workflows and boost efficiency, and that’s where Docling comes in! As an open-source document parsing tool, it’s designed to effortlessly support the analysis and conversion of various common document formats! 🌟🎉
1. Docling: A Magical Tool for a New Era of Document Parsing 🌟
Docling is an open-source document parsing tool that aims to provide users with a fast and easy experience for document import and export! 📁
It supports a wide array of document formats, including PDF, DOCX, PPTX, XLSX, images, HTML, AsciiDoc, and Markdown, making it a veritable kaleidoscope for document processing! 🎨 This variety offers users a broad range of use cases and flexibility, ensuring that Docling can handle anything from everyday work needs to specialized document processing tasks with ease! 💪
In the realm of document parsing, Docling stands out with its exceptional format conversion capabilities and powerful document comprehension abilities, allowing users to tackle any situation with grace, effectively simplifying complex document operations! 🎊
2. The Unique Appeal of Docling: Key Features That Impress ✨
Docling’s charm lies not only in its extensive range of supported document formats! 🚀 It also boasts several impressive key features:
- PDF comprehension: Docling goes beyond basic text parsing by accurately interpreting complex page layouts and tables, providing added convenience that enhances processing efficiency 📊.
- Unified document representation format: With the DoclingDocument structure, users can enjoy a standardized document representation format, making subsequent operations more convenient and eliminating redundant hassle ⚙️.
- Easy tool integration: Docling seamlessly integrates with major tools like LlamaIndex and LangChain, highlighting its strengths in RAG/QA application scenarios 💪.
- User-friendly command-line interface: A simple and efficient command-line interface makes operations a breeze, supporting effective document processing, truly achieving the goal of “simple and efficient” ⌨️.
3. Why Developers Favor Docling: Reasons to Choose It 💡
So, why are developers so fond of Docling? 🤔
- Convenient installation experience: Docling can be easily installed using popular package management tools like pip, fully supporting major operating systems such as macOS, Linux, and Windows, covering most user needs 🌐.
- Outstanding performance: Regardless of the complexity of the document conversion tasks, Docling delivers efficient results, significantly boosting productivity and saving time ⏱️.
- High-quality documentation and support resources: Docling provides comprehensive documentation and support information, ensuring users won’t feel lost while learning and applying it, easily conquering any questions or challenges during use 📚.
- Continuous updates and cutting-edge technology: The Docling team, backed by leading technical expertise, continually rolls out new features to keep Docling up-to-date and aligned with evolving user needs! 🔄
Whether it’s daily document processing or specialized requirements, Docling is here to help users break through traditional document operation bottlenecks, enhancing the speed of information extraction and processing to deliver an unprecedented document experience! 🌈
4. Installing Docling 🚀
Ready to start using Docling? First, make sure you have Python and pip installed on your computer, as they are prerequisites for installing Docling. Next, simply execute the following installation command in your terminal (command line):
pip install docling
📦 With just that, the command will automatically download and install Docling along with all its dependencies. Once the installation is complete, you should see a success message in the terminal, meaning you’re all set to start using Docling! 🎊
5. Example Scenarios 📄
Now, let’s demonstrate how to use Docling for document format conversion through some practical examples! ✨ These examples will help you grasp the basic usage of Docling.
5.1 Example 1: Converting a PDF File from a URL 🌐
You can directly convert a PDF by specifying its URL. Here’s an example:
from docling.document_converter import DocumentConverter
source = "https://arxiv.org/pdf/2408.09869" # This source is the URL of the PDF file
converter = DocumentConverter() # Create an instance of DocumentConverter
result = converter.convert(source) # Use the convert method to parse the PDF into a format Docling can process
print(result.document.export_to_markdown()) # Output the converted Markdown format
🔍 In this snippet, we start by importing the DocumentConverter class and create an instance of the converter. The convert method parses the PDF document from the provided URL and converts it into a Docling-processable object. Finally, we use the export_to_markdown method to output the conversion result in Markdown format, and you’ll see a clean and organized document! ✨
5.2 Example 2: Converting from a Local Document 🖥️
If you have a local Word document (e.g., example.docx), you can easily convert it using the code below:
from docling import DocumentConverter
converter = DocumentConverter() # Create an instance of Document Converter
output = converter.convert("example.docx", format="markdown") # Convert the local document to Markdown format
print(output) # Print the output result
📂 The input file path can be any valid Word file path on your local system, and the converted result will be returned as a Markdown format string, ready for you to print and review its text structure and content! 🧐
5.3 Example 3: Configuring PDF Conversion Options ⚙️
Docling allows users to customize various conversion parameters based on their needs, such as controlling how tables are handled during PDF conversion. Here’s an example:
from docling.datamodel.base_models import InputFormat
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.pipeline_options import PdfPipelineOptions, TableFormerMode
pipeline_options = PdfPipelineOptions(do_table_structure=True) # Enable table structure handling
pipeline_options.table_structure_options.mode = TableFormerMode.ACCURATE # Employ a more accurate table handling mode
doc_converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options) # Set PDF conversion options
}
)
🔑 In this code, we’ve imported a few necessary classes and set up PdfPipelineOptions, where we turn on the do_table_structure parameter to retain more layout information. Then, these options are passed into the DocumentConverter to ensure customized processing logic during PDF conversion, increasing accuracy and readability! 🎯
5.4 Example 4: Chunking Documents with a Chunker 📦
Docling offers the ability to chunk documents efficiently, using HybridChunker to manage text effectively. Here’s a sample:
from docling.document_converter import DocumentConverter
from docling.chunking import HybridChunker
conv_res = DocumentConverter().convert("https://arxiv.org/pdf/2206.01062") # Convert the document
doc = conv_res.document # Extract the parsed document object
chunker = HybridChunker(tokenizer="BAAI/bge-small-en-v1.5") # Set the tokenizer
chunk_iter = chunker.chunk(doc) # Execute chunking process
print(list(chunk_iter)[11]) # Print the output of the 12th chunk
🚀 In this demonstration, we first convert an online PDF document using DocumentConverter, then employ HybridChunker for chunking. This functionality is especially useful when dealing with large documents, allowing you to process text incrementally or retrieve specific chunks as needed. Here, we extracted and printed the 12th chunk! 😊
5.5 Example 5: Converting Documents from a Binary Stream 💻
If you have a binary stream of document data, processing it using BytesIO is also straightforward and effective:
from io import BytesIO
from docling.datamodel.base_models import DocumentStream
from docling.document_converter import DocumentConverter
buf = BytesIO(your_binary_stream) # Wrap your binary stream with BytesIO
source = DocumentStream(name="my_doc.pdf", stream=buf) # Create a document stream object
converter = DocumentConverter()
result = converter.convert(source) # Convert the document stream
⚡ Here, we created a virtual file object using BytesIO, wrapping the binary stream within it. Then we created a document stream object with DocumentStream and finally executed the conversion with DocumentConverter. This method is particularly convenient when handling temporary data or data received from the web! 💡
Whether you’re looking to streamline workflows or tackle complex document processing tasks, Docling is an indispensable ally! Come experience it for yourself! 🌈